Predict prices for houses in the area of Boston
Boston house prices is a classical dataset for regression. This article shows how to make a simple data processing and train neural network for house price prediction.
Boston house prices is a classical example of the regression problem. This article shows how to make a simple data processing and train neural network for house price forecasting.
Dataset can be downloaded from many different resources. In order to simplify this process we will use scikit-learn library. It will download and extract and the data for us.
from sklearn import datasets
dataset = datasets.load_boston()
data, target = dataset.data, dataset.target
We can print few first rows from the dataset just to make sure that
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD |
|---|---|---|---|---|---|---|---|---|
| 0.00632 | 18 | 2.31 | 0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1 |
| 0.02731 | 0 | 7.07 | 0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2 |
| 0.02729 | 0 | 7.07 | 0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2 |
| 0.03237 | 0 | 2.18 | 0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3 |
| 0.06905 | 0 | 2.18 | 0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3 |
| TAX | PTRATIO | B | LSTAT | MEDV |
|---|---|---|---|---|
| 296 | 15.3 | 396.90 | 4.98 | 24.0 |
| 242 | 17.8 | 396.90 | 9.14 | 21.6 |
| 242 | 17.8 | 392.83 | 4.03 | 34.7 |
| 222 | 18.7 | 394.63 | 2.94 | 33.4 |
| 222 | 18.7 | 396.90 | 5.33 | 36.2 |
Data contains 14 columns. The last column MEDV is a median value of owner-occupied homes in $1000’s. The goal is to predict this value. Other columns we can use for neural network training.
It’s quite hard to understand data just from the column names. Scikit-learn also provides description.
print(dataset.DESCR)
- CRIM - per capita crime rate by town
- ZN - proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS - proportion of non-retail business acres per town
- CHAS - Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX - nitric oxides concentration (parts per 10 million)
- RM - average number of rooms per dwelling
- AGE - proportion of owner-occupied units built prior to 1940
- DIS - weighted distances to five Boston employment centres
- RAD - index of accessibility to radial highways
- TAX - full-value property-tax rate per $10,000
- PTRATIO - pupil-teacher ratio by town
- B - 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT - % lower status of the population
There are 13 continuous attributes (including “class” attribute “MEDV”) and 1 binary-valued attribute. There are no columns that have multiple categories, which simplifies initial data processing..
From the table above you can notice that every column has values in different scales. It might slow down or completely break networks convergence. In order to fix this issue, we should normalize values in every column. One of the simplest way to do it is to map every value into range between 0 and 1, where maximum value in every column will be equal to 1 and the smallest one - to 0.
from sklearn import preprocessing
data_scaler = preprocessing.MinMaxScaler()
target_scaler = preprocessing.MinMaxScaler()
data = data_scaler.fit_transform(data)
target = target_scaler.fit_transform(target.reshape(-1, 1))
After transformation data looks like this.
| CRIM | ZN | INDUS | CHAS | NOX | ... |
|---|---|---|---|---|---|
| 0.000000 | 0.18 | 0.067815 | 0 | 0.314815 | ... |
| 0.000236 | 0.00 | 0.242302 | 0 | 0.172840 | ... |
| 0.000236 | 0.00 | 0.242302 | 0 | 0.172840 | ... |
| 0.000293 | 0.00 | 0.063050 | 0 | 0.150206 | ... |
| 0.000705 | 0.00 | 0.063050 | 0 | 0.150206 | ... |
Neural networks are prune to overfitting and we always need to have validation dataset that we will use to assess networks performance after the training.
from sklearn.model_selection import train_test_split
from neupy import utils
# Make sure that split between train and
# validation datasets will be reproducible
utils.reproducible()
x_train, x_test, y_train, y_test = train_test_split(
# 85% of the data we will use for training
# and the other 15% will be used for validation
data, target, test_size=0.15
)
Since we have all the data the last thing that we need is a neural network. We can design simple network with only one hidden layer.
from neupy.layers import *
# Number of features that we want
# to use during the training
n_inputs = 13
# Number of outputs in the network. For the house price
# forecasting we want to predict single value per every
# input sample.
n_outputs = 1
network = join(
# This layer doesn't do any computation. It just
# defines how many inputs network should expect.
Input(n_inputs),
# Hidden layer. Number of neurons can be adjusted
# in order to improve performance or deal with overfitting
Sigmoid(50),
# Sigmoid outputs values between 0 and 1 and all
# the prices that we want to predict has been rescaled
# to the same range.
Sigmoid(n_outputs),
)
Now that we have the our network we can use one of the large training algorithms supported by neupy. Our datasets is quite small and network has small number of parameters. For cases like this we can take advantage of the more algorithms that can converge much faster. I’ll use Levenberg-Marquardt, but you can feel free to experiment with different algorithms.
from neupy import algorithms
optimizer = algorithms.LevenbergMarquardt(
# First argument has to be neural network
network,
# With this option enabled network shows its configuration
# before the training and its progress during the training
verbose=True,
# In order to avoid showing information about
# network training progress after every epoch we can
# do it less frequently, for example, every 5th epoch.
show_epoch=5,
)
Output after initialization might look like this
Main information
[ALGORITHM] LevenbergMarquardt
[OPTION] loss = mse
[OPTION] mu = 0.01
[OPTION] mu_update_factor = 1.2
[OPTION] show_epoch = 5
[OPTION] shuffle_data = False
[OPTION] signals = None
[OPTION] target = Tensor("placeholder/target/sigmoid-10:0", shape=(?, 1), dtype=float32)
[OPTION] verbose = True
[TENSORFLOW] Initializing Tensorflow variables and functions.
[TENSORFLOW] Initialization finished successfully. It took 0.30 seconds
And finally, we can use our data in order to train the network. In addition, neupy allows to specify validation datasets. It won’t use it for training. Instead, at the end of every epoch it will use validation data to estimate network forecasting performance on the unseen data.
optimizer.train(x_train, y_train, x_test, y_test, epochs=30)
Output during the training might look like this
#1 : [224 ms] train: 0.046980, valid: 0.032002
#5 : [76 ms] train: 0.009437, valid: 0.013484
#10 : [75 ms] train: 0.007141, valid: 0.010253
#15 : [77 ms] train: 0.004664, valid: 0.008936
#20 : [75 ms] train: 0.003780, valid: 0.009333
#25 : [75 ms] train: 0.003117, valid: 0.008975
#30 : [77 ms] train: 0.002608, valid: 0.009507
It’s also useful to visualize network training progress using line plot. In the figure below you can see two lines. One line shows training error and the other one validation error.
optimizer.plot_errors()
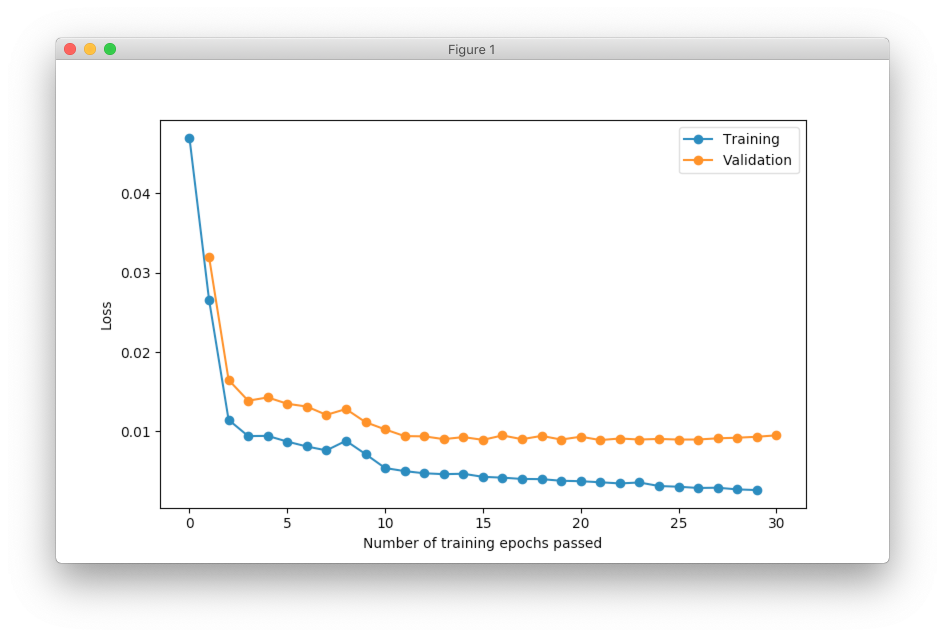
We typically want to see decrease for the validation error. The training error might be useful during debugging. For example, it might be used in order to see if network overfits.
During the training we used mean squared error as a loss function on the scaled prediction values. We can use different function in order to measure network’s forecasting performance. For example, we can use Root Means Squared Logarithmic Error (RMSLE) and compare prediction to the exact value that were scaled back to the original scale.
import numpy as np
def rmsle(expected, predicted):
log_expected = np.log1p(expected + 1)
log_predicted = np.log1p(predicted + 1)
squared_log_error = np.square(log_expected - log_predicted)
return np.sqrt(np.mean(squared_log_error))
y_predict = optimizer.predict(x_test).round(1)
error = rmsle(
target_scaler.inverse_transform(y_test),
target_scaler.inverse_transform(y_predict),
)
print(error) # ~0.18
The final result is quite good for the first prototype.